What Are the 5 Key Stages of the Resilience Lifecycle Framework?
In this fast-paced digital world, disruptions like network outages or cyber attacks can hit hard. Technical teams, software architects, SREs, DevOps engineers, and cloud specialists know this all too well. They build and run complex systems that must stay up no matter what. That’s what the 5 key stages of the resilience lifecycle framework come in. This structured approach helps you embed toughness into every part of your operations. This tool changes “oh no, it’s broken!” into “we are ready, no problem!”
If your app stops working for just one hour, big companies can lose $100,000. That is a lot of money!
The resilience lifecycle is like a simple map. It has five easy steps: plan, build, test, run, and learn. It helps your apps get back up super fast when something goes wrong.
This story explains everything in simple words. We will look at each step with fun tips and examples. No matter if you make apps or help run a team, you will leave with easy things you can do right now! Let’s build systems that don’t just survive—they thrive.
Why Resilience Matters in Modern IT and Cloud Environments
Resilience isn’t a buzzword. It’s the backbone of reliable operations. In simple terms, resilience meaning boils down to your system’s ability to handle shocks and keep delivering value. For technical pros like you, it means fewer alerts at 3 a.m. and happier stakeholders.
Consider the rise of cloud adoption. Over 90% of enterprises use multi-cloud or hybrid setups, per a Flexera State of the Cloud Report. But with great power comes great risk: More connections mean more points of failure. Enter the resilience lifecycle framework process. It mirrors the software development lifecycle (SDLC) you already know, weaving in safeguards from day one.
The Roots of the Resilience Lifecycle Framework
AWS made this resilience map in 2023. It is part of their big help book.
They learned it by fixing problems for big companies like Vanguard Group for many years. Now they teach everyone how to plan ahead so things don’t break, instead of just running to put out fires. AWS saw teams struggling with always-on demands amid remote work and quick releases. Their solution? A cycle that loops through five stages, much like agile sprints but focused on durability.
There are bigger versions too! Some are made for whole teams and companies. They help everyone get ready together, not just the computers. It’s like a plan for the people part of staying strong! These overlap with AWS’s tech slant, making the framework versatile. For IT leaders, it’s about balancing cost and complexity. Add redundancy? Sure, but not if it bloats your budget.
Who Benefits Most?
- Technical Teams and Software Architects: You design the blueprints. This framework ensures system fault tolerance from the start.
- SREs and DevOps Engineers: Your world is monitoring and ops. Use it to automate tests and cut mean time to recovery (MTTR).
- Cloud Engineers: In AWS or multi-cloud, it aligns with tools like Resilience Hub for steady-state checks.
- IT Decision-Makers and Leaders: CTOs weigh trade-offs. Set resilience objectives that match business goals without over-engineering.
- Project Managers and Risk Pros: Tie it to the business continuity lifecycle for holistic plans.
- Consultants and Stakeholders: Embed it into culture for long-term wins.
Understanding the Resilience Lifecycle: A High-Level View
Before we zoom in, picture the resilience framework process as a wheel. It spins continuously, with no endpoint. Start with goals, build smart, test hard, run smooth, then learn and repeat. This lifecycle approach to resilience fits distributed systems perfectly, where one glitch can cascade.
Unlike one-off audits, it’s iterative. Apply it per app or across your portfolio. Tools like AWS Fault Injection Simulator (FIS) plug right in for chaos testing. The payoff? Faster innovation with less fear of breakage.

Now, let’s unpack the core: What are the 5 key stages of the resilience lifecycle framework?
Stage 1: Set Objectives – Define Your Resilience North Star
The first wheel sets objectives. Here, you map out what “resilient enough” looks like. Skip this, and you’re guessing on investments.
Why This Stage Kicks Off the Framework
Without clear targets, teams chase shadows. Think RTO (Recovery Time Objective) and RPO (Recovery Point Objective). RTO is how fast you recover; RPO is how much data you can lose. For a banking app, RTO might be 15 minutes. For analytics? Hours.
AWS recommends starting with business impact analysis. List critical apps, user stories, and metrics. Use SLOs (Service Level Objectives) to quantify.
Actionable Steps for Technical Teams
- Map Critical Paths: Identify must-have functions. Tools like AWS Resilience Hub score your setup against goals.
- Set Measurable Targets: Aim for 99.99% uptime? Document it.
- Involve Stakeholders: Chat with ops and business leads for buy-in.
Example: A DevOps team at a retail firm sets RPO at 5 minutes for checkout services. They use this to justify multi-AZ deployments, cutting outage risks by 40%.
For project managers, this ties into resilience planning phases. It ensures resources align with risks.
Tip: Review objectives quarterly. As apps evolve, so do threats.
This stage sets the tone. Next, you turn goals into reality.
Stage 2: Design and Implement – Build Resilience into the Bones
Now comes the fun part: Design and implementation of resilience. You architect with failure in mind. It’s where theory meets code.
Core Elements of This Stage
Draw from the AWS well-architected framework, especially its Reliability Pillar. Key moves? Understand dependencies, pick DR strategies, and model failures.
- Understand Dependencies: Map services, APIs, and externals. A glitch in a third-party payment gateway? Plan for it.
- DR Strategies: Backup, pilot light, warm standby—choose based on RTO/RPO.
- CI/CD Resilience: Bake in automated checks. Fail fast, recover faster.
AWS stresses fault isolation: Use AZs and Regions to contain blasts.
Practical Tips for SREs and Architects
- Resilience Modelling: Sketch failure scenarios. Tools like the resilience analysis framework help spot weak links.
- Fail Safely: Implement circuit breakers in microservices. Libraries like Hystrix or Resilience4j make it easy.
- Trade-Off Reviews: Hold Operational Readiness Reviews (ORRs) before launch.
Real-World Example: Vanguard Group redesigned their trading platform using this stage. They added multi-region failover, slashing recovery from hours to minutes. Result? Zero major outages in a volatile market year.
For cloud engineers, integrate resilience in cloud systems via services like Amazon Route 53 for DNS failover.
Pro Tip: Start small. Prototype one service, then scale patterns org-wide.
This build phase ensures your system has guardrails. But does it hold up? Time to test.
Stage 3: Evaluate and Test – Prove It Works Under Fire
Testing isn’t optional; it’s proof. In resilience evaluation and testing, you simulate doom to validate designs.
Why Testing is Non-Negotiable
Assumptions kill. Real disruptions? Unpredictable. Chaos engineering reveals cracks early.
AWS pushes game days and canary deployments. Run scheduled tests mimicking user traffic.
Step-by-Step Testing Guide
- Baseline Assessments: Use AWS Resilience Hub for automated scans.
- Chaos Experiments: Inject faults with FIS. Kill a node—does traffic shift?
- Load and Stress Tests: Ramp up demand. Monitor with CloudWatch.
Example in Action: A SaaS provider tests failover weekly. When a real AZ outage hit, their app stayed up 99.9%, saving $50K in lost revenue.
For DevOps, this stage sharpens incident response and adaptation. Script everything for repeatability.
Beginner Note: New to chaos? Start with read-only tests.
Testing builds confidence. Now, keep it running day-to-day.

Stage 4: Operate – Keep the Engine Humming
Launch day arrives. Operational resilience management takes over. You monitor, tweak, and maintain.
Daily Ops with Resilience in Mind
Observability is king. Set up dashboards for key metrics: Latency, error rates, throughput.
- Event Management: Automate alerts. Use Amazon EventBridge for workflows.
- Continuous Checks: Schedule Well-Architected reviews. Drift detection spots config slips.
Per AWS, iterate pre-prod tests into prod game days.
Tips for Cloud and Ops Teams
- Proactive Monitoring: AI-driven anomaly detection in CloudWatch.
- Scalability Drills: Auto-scale during peaks.
- Vendor Sync: Review SLAs with partners1.
Case Study: An e-commerce giant uses this for Black Friday. Real-time tweaks handled 3x traffic spikes without a hitch.
This stage prevents small issues from snowballing. But when big ones hit?
Stage 5: Respond and Learn – Turn Setbacks into Superpowers
Disruptions happen. Respond and learn is your playbook for handling and harvesting insights.
Handling the Heat
Activate response plans: Clear comms, escalation paths, resource shifts.
Post-incident: Blameless reviews. What broke? Why? Fix it.
AWS advises incident reports, metrics audits, and knowledge bases.
Learning Loops for Growth
- Root Cause Analysis: Use 5 Whys.
- Update Models: Feed back into Stage 1.
- Train Teams: Drills build muscle.
Example: After a DDoS, a fintech firm adapted with better WAF rules. Next attack? Mitigated in seconds.
For risk managers, this closes the risk management lifecycle loop.
Key Advice: Celebrate learning, not blaming. It fosters innovation.
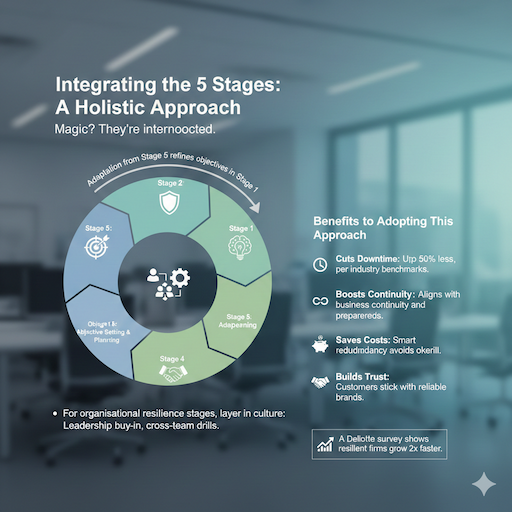
Integrating the 5 Stages: A Holistic Approach
Magic? They’re interconnected. Adaptation from Stage 5 refines objectives in Stage 1. For organisational resilience stages, layer in culture: Leadership buy-in, cross-team drills.
Benefits of Adopting This Approach
- Cuts Downtime: Up to 50% less, per industry benchmarks.
- Boosts Continuity: Aligns with business continuity and preparedness.
- Saves Costs: Smart redundancy avoids overkill.
- Builds Trust: Customers stick with reliable brands.
A Deloitte survey shows resilient firms grow 2x faster.
Tailoring the Framework to Your Role
For Technical Teams: Hands-On Implementation
As an SRE, automate Stage 3 tests in your pipeline. Use AWS resiliency best practices like multi-AZ ELBs.
Step-by-Step Guide:
- Audit the current setup.
- Map to stages.
- Pilot on one app.
- Scale with metrics.
For Leaders: Strategic Alignment
CTOs use it for roadmaps. Balance proactive risk mitigation with budgets.
For Project Managers: Bridging Tech and Business
Incorporate into the resilience lifecycle framework for project managers2. Add gates per stage.
Example: In agile, sprint reviews include resilience checks.
Real-World Applications and Case Studies
Cloud Systems Success Story
Netflix’s Chaos Monkey? Pure Stage 3. They inject failures daily, ensuring digital infrastructure resilience.
AWS in Action
Vanguard’s shift: Dedicated resilience office, full lifecycle adoption. Outages dropped 70%.
Broader Organisational Wins
A healthcare provider used crisis response planning in Stage 5 post-ransomware. Adapted with zero-trust, preventing repeats.
Common Challenges and How to Overcome Them
- Challenge: Resistance to Change – Solution: Start small, show quick wins.
- Challenge: Tool Overload – Solution: Pick 2-3 like Resilience Hub and FIS.
- Challenge: Measuring ROI – Solution: Track MTTR and uptime pre/post.
Difference Between Resilience Stages and Disaster Recovery Phases: DR is tactical (backup/restore); resilience is a full lifecycle, including prevention.
Advanced Topics: Maturity and Scaling
Assess with a resilience maturity model. Level 1: Reactive. Level 5: Predictive.
Scale via resilience strategy framework: Central team sets standards, squads adapt.
For how to implement the resilience lifecycle framework in an organization, begin with workshops. Train on resilience development stages.
FAQs
What is the resilience lifecycle explained for beginners?
It’s a 5-stage cycle: Set goals, design tough systems, test them, run smoothly, and learn from hiccups. Like tuning a car for any road.
How to evaluate and test resilience in the lifecycle framework?
In step 3, you play “break the system” games with special chaos tools that make fake problems. You also do check-up audits. You measure if the system comes back fast enough (RTO) and if you lose any work (RPO). It’s like a fire drill for computers!
Benefits of adopting a resilience lifecycle approach?
You get way less “oops the app is down” time, you save lots of money, and your company can grow faster because customers trust you. Everything stays calm and happy even on bad days!
Integrating resilience stages into IT and operations teams?
Put resilience jobs inside your normal work steps (SDLC). In weekly team meetings, everyone quickly says “Are we still strong?” It becomes a normal habit, like brushing teeth!
Why does the resilience lifecycle framework matter for risk management?
It helps you guess problems before they happen instead of running around when they do. It finds and fixes weak spots early, so nothing big and scary surprises you later!
What are the five phases of the resilience lifecycle framework?
Same as the key stages: Objectives, Design/Implement, Evaluate/Test, Operate, Respond/Learn.
Conclusion
The resilience lifecycle has 5 easy steps to make things super strong. First, you decide what you want, like “my app must never stop.” Then you build it smart and safe. Next, you test it a lot by pretending things break. After that, you run it every day and keep it happy. Last, you learn from any oops moments and get even better.
These 5 steps help your app keep working and stay happy no matter what! For technical teams, leaders, and planners, it’s more than steps; it’s a mindset3. Embed resilience best practices, and watch your operations soar. As disruptions evolve, so must we. Start today: Pick one stage, apply it to a key app, and iterate.
References
- Medium: Resilience Lifecycle Insights – Beginner-friendly breakdown with IT examples, ideal for DevOps starting the resilience implementation process. Link ↩︎
- Project Manager Template: 5 Key Stages Explained – Practical guide for project managers on organisational resilience stages, including why they matter for continuity planning. Link ↩︎
- AWS Prescriptive Guidance: Resilience Lifecycle Framework – Official intro to the AWS resilience lifecycle, with stages and cloud examples for SREs and architects. Link ↩︎